OpenVLA finetuning with online RL
OpenVLA is a 7B parameter open-source vision-language-action model (VLA) pretrained on the Open X-Embodiment dataset. It is a representative of generalist robot manipulation policies that can generalize to open-ended tabletop scenarios. However, according to my observation, the pretrained OpenVLA struggles in quite some scenarios. It can get 50% success rate on familiar tasks but quickly drops to <10% in novel scenes. Even in the former case, 50% is no where near a perfect policy for robust manipulation.
In this article, we will dive deep into technical details and finetune OpenVLA with sparse RL rewards.
One might wonder: aren’t VLA models supposed to be only finetuned by supervised learning on offline datasets? After all, these VLA models are
- large in size, which makes optimization nontrivial unless strong supervision signal is provided, and
- high in forward/backward latency, which further prolongs an already lengthy RL training process.
Well, for (1), there has been lots of success (e.g., DeepSeek R1) using RL to post-train LLMs to achieve tasks in the language space. Moreover, some recent research like ConRFT and VLA-RL is already attempting to bring these advances to VLAs in robotics.
For item (2), traditional RL with a small model spends lots of time on random exploration until some positive feedback is received from the environment. I believe that this blinded exploration is the major factor contributing to data inefficiency and long training time. In contrast, a pretrained VLA policy already has some sense or even success of achieving a given task. This helps reduce the exploration time and compensates for its high policy latency. So even without epsilon greedy or an entropy term encouraging exploration, a VLA with a correct implementation will be able to perform meaningful exploration based upon the existing policy prior.
But the most important question we will answer in this article is: can we leverage the generalization ability of a VLA for RL on downstream tasks? That is, if we finetune OpenVLA only on a small subset of instructions and gain a significant performance improvement, will a similar improvement also be seen on other different but similar instructions? For example, “put A in B” is RL-improved from 50% to 99%, will “put A in C” (not seen during finetuning) also have such an increase? (Spoiler: YES!)
We will finetune OpenVLA with online (on-policy) RL. Unlike existing works that aim to innovate RL algorithms specifically for VLAs, this article focuses on improving OpenVLA’s model to make it “ready” for existing RL algorithms. Once the change on the architecture is done, the rest is just to follow typical RL training practices. We choose two representative algorithms: REINFORCE and PPO (strictly it’s off-policy but its pipeline has an on-policy flavor like REINFORCE and actor-critic; so I will still call it on-policy in the following).
Comparison between VLA and VLM in terms of action decision process
Comparison between VLA and VLM. Gray arrows represent dependency/attention.
|
|---|

First I’d like to quickly go over some differences and similarities between the action decision process of a VLA and that of a VLM.
Decision process of VLM: essentially it has only one-time interaction with the environment that provides the initial prompt (text and image) for action generation. The model then keeps generating actions until timeout or <eos> is produced. This process is non-Markovian, because its reward depends on the history of past actions. However, by adding past actions into the observation, we can convert this system into a Markov Decision Process (MDP), and apply typical RL algorithms to it. The RL difficulty, however, exactly resides in the exponentially increased state space caused by past actions.
Decision process of VLA: a VLA has multiple rounds of interactions with the environment, so it is affected much more by external events and noises. Within one interaction, its action decision process is very similar to that of a VLM: non-Markovian unless we add previously generated action tokens into the observation or assume independence among action tokens. Here, only a small fixed number of action tokens are generated for one interaction. For this reason, sometimes it might be more convenient to treat them as one action from a composite action space. Across interactions, it is a typical MDP if we do not consider visual memory. As a result, the attention is sparse that we only attend to the most recent image tokens and the text tokens. Furthermore, if we assume the MDP is stationary, we can reset the position ids of the current image tokens to those used for the first image.
Make OpenVLA “RL ready”
We are going to use the official codebase of OpenVLA. However, several issues of the original code need to be addressed before moving on. (Disclaimer: these issues might have been fixed in follow-up works or codebases, which I didn’t verify at the time of writing this article. Check e.g., OpenVLA-mini, OpenVLA-OFT, and other related code repos.)
Issue 1: Batched action prediction
Batched rollout is a critical feature for on-policy RL. This applies to whether we are training in simulation which naturally supports batched environments, or we want to do RL-in-Real with multiple robots for data collection but just one GPU for batched inference.
Unfortunately, OpenVLA doesn’t support batched generation in its native form. If we go to PrismaticForConditionalGeneration.forward(), we will notice:
if input_ids.shape[1] == 1:
assert input_ids.shape[0] == 1, "Generation is only currently supported for batch size of 1!"
Also in PrismaticForConditionalGeneration.prepare_inputs_for_generation(), there is another similar assertion:
"""Borrowed from `LlamaForCausalLM` and simplified for batch size = 1; mirrors original PrismaticVLM logic."""
if ((input_ids is not None) and (input_ids.shape[0] > 1)) or (
(inputs_embeds is not None) and (inputs_embeds.shape[0] > 1)
):
raise ValueError("Generation with batch size > 1 is not currently supported!")
OpenVLAForActionPrediction inherits this class, so clearly the authors don’t expect us to perform batched action generation.
OK let’s first try simply removing these two assertions and test if anything could go wrong. It turns out that for a batch size of 2, if we fix the first instruction but make the second instruction longer or shorter, the predicted action (taking
OpenVLA adopts right padding. So for two token sequences with different lengths, the padding result is illustrated as below:

During training, the action tokens are concatenated with instruction tokens first and then the padding is applied. However, for generation, we need to pad the instruction tokens first before predicting action tokens. This difference does not matter if the model ignores padding tokens correctly, but is that the case?
I noticed that in PrismaticForConditionalGeneration.forward(), position_ids is always hardcoded to be None. Prismatic uses Llama2 as the language model, so after more digging into Llama2’s code, in LlamaModel.forward(), I found:
if cache_position is None:
past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
cache_position = torch.arange(
past_seen_tokens, past_seen_tokens + inputs_embeds.shape[1], device=inputs_embeds.device
)
if position_ids is None:
position_ids = cache_position.unsqueeze(0)
This means that regardless of whether cache is enabled, if position_ids is not
provided, it will be a consecutive integer sequence starting from 0. In other words, padding tokens will impact position ids of non-padding tokens. To fix this, we can provide position ids manually, computed by
position_ids = attention_mask.long().cumsum(-1) - 1
position_ids.masked_fill_(attention_mask == 0, 1)
Another issue exists for the attention_mask argument for generation with cache (activated when generating action tokens after the first one). This argument is also hardcoded to be None for LlamaModel.forward(), and thus attention computation will not exclude padding tokens. The solution is to properly compute the attention mask:
# PrismaticForConditionalGeneration.forward()
if attention_mask is not None:
vision_attention_mask = torch.full(
(attention_mask.shape[0], self._patch_embeddings_n),
fill_value=True,
dtype=attention_mask.dtype,
device=attention_mask.device,
)
# Generator will only incrementally add one bit to ``attention_mask`` outside of this call.
# See ``GenerationMixin._update_model_kwargs_for_generation()``
# So every time we have to manually fill in vision attention mask.
attention_mask = torch.cat([
attention_mask[:, :1], vision_attention_mask,
attention_mask[:, 1:]
]
and pass it to LlamaModel even for cached generation.
After addressing these two issues, I could get exactly the same generation result no matter how padding tokens are applied to an instruction!
Issue 2: Action token sampling
Exploration is critical for any RL policy learning. So instead of taking do_sample=True and temperature=1 when calling OpenVLAForActionPrediction.prediction_action(). But there is one detail we need to pay attention to in that function:
# Run VLA inference
generated_ids = self.generate(input_ids, max_new_tokens=self.get_action_dim(unnorm_key), **kwargs)
# Extract predicted action tokens and translate into (normalized) continuous actions
predicted_action_token_ids = generated_ids[0, -self.get_action_dim(unnorm_key) :].cpu().numpy()
discretized_actions = self.vocab_size - predicted_action_token_ids
discretized_actions = np.clip(discretized_actions - 1, a_min=0, a_max=self.bin_centers.shape[0] - 1)
normalized_actions = self.bin_centers[discretized_actions]
We can see that after the action token ids are generated, they are first subtracted from self.vocab_size because the reserved range [self.vocab_size-256, self.vocab_size-1] represents action id range that is used to discretize the original continuous action. So subtracting it from self.vocab_size transforms it back to [1,256] (action bin index+1). But then something strange follows: the index is clipped into the valid range! It does not make any sense at all when we clip a discrete variable because two discrete values that are close to each other don’t necessarily represent similar meanings. So why this hack?
After some debugging with different test cases, I realized that there are two reasons:
- The original
self.bin_centershas one bin missing at the upper action boundary of 1 whose id is actually valid for training and prediction. To see this inActionTokenizer.__call__:
action = np.clip(action, a_min=float(self.min_action), a_max=float(self.max_action))
discretized_action = np.digitize(action, self.bins)
Note that np.digitize generates indices in {1,2,...,len(self.bins)}, where the last index corresponds to self.max_action. However, self.bin_centers discards this index for some reason
self.bin_centers = (self.bins[:-1] + self.bins[1:]) / 2.0
We can simply add one more bin center to avoid clipping.
- For sampling, there is no guarantee that the sampled id always falls in the action id range
[self.vocab_size-256, self.vocab_size-1], because softmax is taken over the entire vocabulary. Given unfamiliar inputs, the model can easily sample ids out of that range. The solution to this problem is also easy: we manually mask out the logits of non-action ids.
class ActionVocabMaskLogitsProcessor(LogitsProcessor):
"""When calling `generate()`, only allow the model to predict action tokens by
manually masking out the logits for non-action tokens as -inf.
"""
def __init__(self, action_token_ids: List[int], vocab_size: int):
"""
Args:
action_token_ids: a list of valid action ids within the vocabulary
vocab_size: vocabulary size
"""
action_mask = torch.zeros(vocab_size, dtype=torch.bool)
action_mask[action_token_ids] = True
# [1, vocab_size]
self._inf_mask = (~action_mask).unsqueeze(0)
def __call__(self, input_ids: torch.LongTensor,
scores: torch.FloatTensor) -> torch.FloatTensor:
# ``scores`` has shape of (batch_size, vocab_size)
inf_mask_expanded = self._inf_mask.expand_as(scores).to(scores.device)
scores = torch.where(
inf_mask_expanded,
torch.full_like(scores, -float('inf')),
# Sometimes a corner case is that all action tokens are already -inf.
# We simply clamp a min score to keep the distribution valid, after
# masking out non-action tokens.
torch.clamp(scores, min=-1e6))
return scores
By passing this logits processor to the predict_action() function, the sampled ids will always be valid. I do believe for OpenVLA pretraining, the authors should have done this masking in the first place. For some reason, masking was not applied.
After addressing the above two issues, now we can sample actions with a temperature of 1, without crashing the code.
"Put the cube on top of the cloth."| argmax | Sampling with temperature=1 |
|---|---|
Notice that how sampling introduces more randomness of the behavior compared to
One additional thing to note: GenerationMixin.generate() disables gradient. After generating actions and obtaining their logits, we cannot directly do back-propagation through the logits, which is inconvenient for on-policy RL. A workaround is to save the rollout actions and later re-evaluate their log probabilities using forward(). For this re-evaluation, we need to apply our custom ActionVocabMaskLogitsProcessor to be consistent with generate().
Issue 3: Off-policyness by logits processing
Lastly, we need to make sure that there is no off-policyness bias introduced in the language model generation process, as we are doing on-policy RL (PPO can handle some off-policyness but it’s still best to avoid any off-policyness from the action sampling process). Formally, given any state GenerationMixin for token sampling:
# In GenerationMixin._sample()
# pre-process distribution
next_token_scores = logits_processor(input_ids, next_token_logits)
Notice how the raw token logits are processed by a list of logits processors. If we print out logits_processor we get
[<openvla.openvla_wrapper.ActionVocabMaskLogitsProcessor object at 0x7d4eb84bfd60>, <transformers.generation.logits_process.TopKLogitsWarper object at 0x7d4efbad1750>]
The first processor is our customized one for masking out non-action logits, and the second processor is inserted by HF for limiting token selection to the k (by default 50) most probable tokens at each step. In fact, we can inspect the scores field of the model output and compare it to logits:
model_outputs = self._model.generate(
output_scores=True,
output_logits=True,
do_sample=True,
...)
scores = torch.stack(model_outputs.scores, dim=1).float()
raw_logits = torch.stack(model_outputs.logits, dim=1).float()
diff = scores.softmax(dim=-1) - raw_logits.softmax(dim=-1)
print("Prob max diff: ", diff.abs().max())
# Prob max diff: tensor(0.0135)
To prevent the discrepancy between sampling scores and logits, the solution is to set num_beams=1, top_k=0, top_p=1. for generate(), which essentially disables beam search, top-k sampling, and nucleus sampling that could possibly change logits. After this is done, we can confirm that the difference between scores and logits is very tiny (not exactly zero because we mask out non-action logits; later when we compute
Task
As a simple verification experiment, I will create
For simplicity, we always have the same instruction “Put the cube on the towel” but the table layout - including a towel and plate - will be randomized across episodes. According to my testing, the initial pretrained OpenVLA policy has only ~0.4 success rate in this scenario.

REINFORCE
REINFORCE is probably the easiest option for finetuning OpenVLA with RL, since it doesn’t require learning additional quantities (e.g., value).
At every training iteration, we first perform policy rollout for a complete episode in each environment. Then each time step of the episode is labeled with discounted returns.
The policy gradient is accumulated over the entire rollout batch of
My result showed that REINFORCE could steadily improve the success rate but the progress was kind of slow. Training with more environments (
 |
|---|
PPO
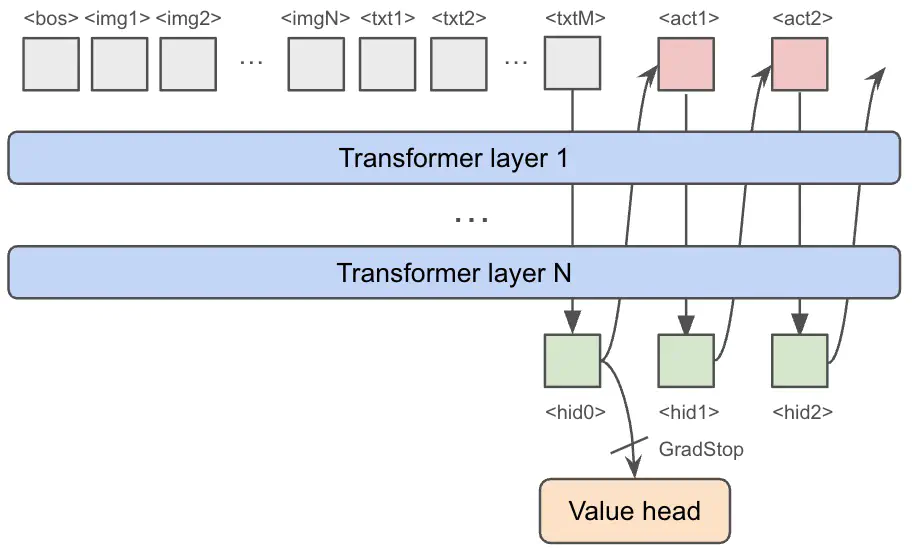
OpenVLA with a custom value head for advantage estimation
 |
|---|
PPO is generally more sample efficient than REINFORCE because it allows off-policy update (multiple optimizer steps per rollout). However, it requires learning a value function for advantage estimation. Typically, PPO uses another network with similar structure for this purpose. But clearly that is not an option here because an OpenVLA model is quite expensive regarding both memory and time, and we don’t want to create a second one.
One solution is to adopt an asymmetric design of policy network and value network. For our downstream task finetuning, the value function can probably be well approximated with a much smaller CNN. But this asymmetric design complicates our pipeline.
My alternative solution was to let the policy and value heads share latent representations until the last several layers. We can attach a learnable value head to the last hidden state layer of OpenVLA. The head is just a simple MLP with two hidden layers:
# ``hidden_size`` is the size of OpenVLA hidden state
value_head = torch.nn.Sequential(
torch.nn.Linear(hidden_size, hidden_size), torch.nn.ReLU(),
torch.nn.Linear(hidden_size, hidden_size // 4), torch.nn.ReLU(),
torch.nn.Linear(hidden_size // 4, 1))
When computing the value, we stop the gradient of the hidden state of the last prompt token (used for generating the first action token), before inputting it to the value head. The gradient stopping is critical here because otherwise value TD learning will destroy policy behavior quickly (see below).
For each rollout batch data, I split it into 20 mini-batches where the PPO gradient is computed for each mini-batch and an optimizer step is taken. So PPO updated model parameters 20x more frequently compared to REINFORCE. The remaining PPO training options (e.g., generalized advantage estimation, advantage normalization, importance clipping, etc) followed the common practices in ALF.
The results are more stable and sample efficient than REINFORCE. The less diversity the rollout data has, the more difficulty the policy will have converging to a success rate of 1. However, note that with the same training iterations, 96 envs has 4x samples (4x less sample efficient) than 24 envs.
 |
|---|
Some demos of the final finetuned policy taking
As mentioned earlier, StopGrad is important for the value head, as demonstrated by the result below.
 |
|---|
Generalization
To test if RL can leverage OpenVLA’s generalization ability, I took one of the PPO models finetuned only on the task “Put the cube on the towel” and directly evaluated it on another instruction “Put the cube in the plate” in the same scenario. Alternatively, I modified the cube color to be red and evaluated the same “Put the cube on the towel” instruction.
| “Put the cube on the towel” (green cube) | “Put the cube in the plate” | “Put the cube on the towel” (red cube) | |
|---|---|---|---|
| Finetuning OOD? | No | Yes (language) | Yes (vision) |
| Before (success rate) | 0.42 | 0.46 | 0.24 |
| After (success rate) | 1 | 0.9 | 0.92 |
It is exciting to see that the success rates of the other two OOD tasks also improve from
Some example policy trajectories on the two OOD tasks are shown below.
| "Put the cube in the plate" | "Put the cube on the towel" (red cube) |
|---|---|
Training setup
I applied LoRA adapters to finetuning OpenVLA. The base model has 4bit quantization while the LoRA weights are in torch.float32. To save VRAM, gradient checkpointing was also enabled. I used DDP for training on 3090 gpus. Each 3090 gpu just has enough VRAM to host 12 environments for graphics rendering and a batch size of 12 for OpenVLA forward-backward. (The VLM reward model also takes some VRAM but since rollout and train are sequential we can offload it to CPU during training.) So
Training times
| Time (seconds) | OpenVLA inference | PaliGemma2 inference | OpenVLA forward-backward | Total |
|---|---|---|---|---|
| Per step (batch size=12) | 2 | 0.75 | 3.75 | 6.5 |
| Per iteration (80 steps) | 160 | 60 | 300 | 520 |
It takes 17 hours for a job that converges in 120 iterations. The time can be reduced to about 6 hours if we use 8 3090s for 24 parallel environments (each DDP rank has a batch size of 3 and 3 parallel environments). It’s interesting to note that with better GPUs, a control frequency of 5HZ, a batch size of 1 for rollout, and async rollout/training, we are expected to get about the same wall-clock time for training the same task in a real-world setting.
Summary
In this article I have shown how to finetune OpenVLA with RL on a downstream task. To do so, I addressed several issues of OpenVLA so that exploration can be done via action sampling in a batched manner, with padding tokens taken care of properly. From the preliminary experiment results, if a VLA model already has a good prior for the task at hand, the policy can improve in a small number of training iterations. More importantly, initial evidence suggests that the generalization ability (wrt. both language and vision) of a VLA can be leveraged by RL on downstream tasks.
Limitation
Current finetuning assumes that OpenVLA already knows how to achieve a downstream task with a certain chance but we want to improve it to be perfect. If it doesn’t know anything about a novel task, supervised finetuning (SFT) on a handful of demos can bootstrap the correct behavior. If no demo is available, extra exploration techniques are needed and it remains to be seen how efficient the current training paradigm is.
Training in real
In real-world applications, to make on-policy RL finetuning possible, typically a fleet of robots is needed to guarantee enough data diversity. With a single robot, we have to roll out the policy for enough episodes before each parameter update. To increase the sample efficiency, we can rely on off-policy RL finetuning, which has more requirements for adapting the VLA model architecture (e.g., computing