On Sim2Real Transfer in Robotics (Part 1/3)
 Image credit: Gemini
Image credit: GeminiWhy Scaling Hasn’t Happened in the World of Robotics
Navigating the landscape of general-purpose robots today, one of the most pressing challenges we face revolves around the lack of data. This scarcity of data, particularly in terms of robot action, stands as a major roadblock hindering the widespread adoption of deep learning models within real-world robotic applications. Without action data, a learning policy will not be supervised to output proper actions given sensor readings.
Part of the problem stems from the sheer diversity in robot designs we’ve concocted thus far. Picture it: robotic dogs, ostriches, humanoids, serpents, disc-shaped — all with their own unique shapes and sizes. And with these diverse designs come an equally varied range of action spaces. Some robots operate with mere 2 dimensions, while others navigate through a vast expanse of 50! Moreover, the meanings these actions represent differ drastically from one robot to another, depending on the actuators a robot is equipped with and how a parameterized action space is chosen. A scalar value of “1” might mean a force of 1 newton applied to an actuator, or a target joint position of 1 degree.

Compare this to us humans. We may come in different shapes and sizes, but at our core, we all share the same basic blueprint: two arms, two legs, and a network of joints peppered throughout our body. This uniformity is a luxury not afforded to our mechanical counterparts.
Because of cross-embodiment, we humans find it arduous to effectively demonstrate tasks for robots. Complicating matters further, locomotion or manipulation skills - essential components of many tasks - are notoriously difficult to articulate using natural language, the primary mode through which humans typically convey their ideas and intentions. Picture this: You’re trying to teach a friend how to ride a bicycle. You can offer some broad strokes about balancing on two wheels, but when it comes down to the nitty-gritty details of how each muscle should move to maintain that balance, words alone fall short. What does this imply? Obtaining action annotated robot data is extremely expensive.
Online, there’s a wealth of video content showcasing humans effortlessly tackling daily tasks, often accompanied by helpful instructions outlining the objectives of each clip. Yet, despite this abundance, these videos typically only capture the evolving state of the environment, lacking the crucial insights into the specific actions required for a particular type of robot to replicate those tasks. This leaves a critical gap for robotic learners.
What about reinforcement learning?
Reinforcement Learning (RL) holds the exciting promise of enabling robots to learn without the need for explicit demonstrations. Instead of being spoon-fed instructions, these robotic learners navigate their environment, receiving feedback on their actions to reinforce positive behaviors and correct mistakes. However, the reality is a bit more complicated. While RL thrives on feedback or rewards, such rewards can be hard to come by in the real world. Meaningful feedback often necessitates human supervisors to intervene, adding a layer of complexity. Moreover, granting robots the freedom to explore comes with safety concerns. There’s the risk of wear and tear on robot hardware, potential damage to objects in the environment, and, most importantly, the safety of people around them. Balancing the potential of RL with these real-world challenges is a crucial step towards unleashing its full potential in robotics.
Simulator
Many robotics researchers advocate for the use of simulators, and for good reason. Simulators offer controlled environments where robots can be trained on a tremendous amount of simulated data without the risks associated with the physical world. Inside a simulator, we can:
- define environments, tasks, and rewards, and let robots explore, learn, and refine their skills, using RL; or
- use planning methods to generate demonstrated action data given the known underlying world model, and let robots learn to imitate the action trajectories.
Either way, a simulator seems a perfect playground for a robot to scale up its abilities.
However, it’s essential to recognize that simulators are not perfect replicas of reality. They’re more like close approximations. Despite the advancements in physics theories and computer graphics, accurately simulating complex physical interactions and rendering realistic scenes demands significant computational resources. Sometimes, achieving an exact simulation or rendering a photorealistic image is so computationally intensive that it becomes practically infeasible with current computer technology. This computational complexity often means that simulations involve simplifications or approximations of graphics and real-world physics.
Indeed, there is no free lunch. While these approximations can provide valuable training data for robots, they may not capture every nuance of the real environment. As a result, there can be discrepancies between simulation and the real world. This is commonly known as the “Sim2Real gap”.
Physics Sim2Real Gap
Physics simulation challenges
Simulating rigid, regularly-shaped objects is relatively straightforward and computation-effective. However, the challenge escalates when dealing with deformable, irregularly-shaped objects, particularly those exhibiting liquid properties. For instance, envision a scenario where a robot arm with two fingers aims to grasp a slippery plastic bag of chips delicately, ensuring that the chips remain intact without being crushed into pieces by excessive finger forces. Simulating this bag of chips involves navigating the dynamic interplay between the individual chips, the bag’s deformability, and accurately modeling the friction dynamics of the bag’s surface. Achieving precise simulations in such scenarios proves to be exceedingly challenging.
| A robot arm tries to grasp a bag of chips. | Illustration of backlash. |
|---|---|
 | 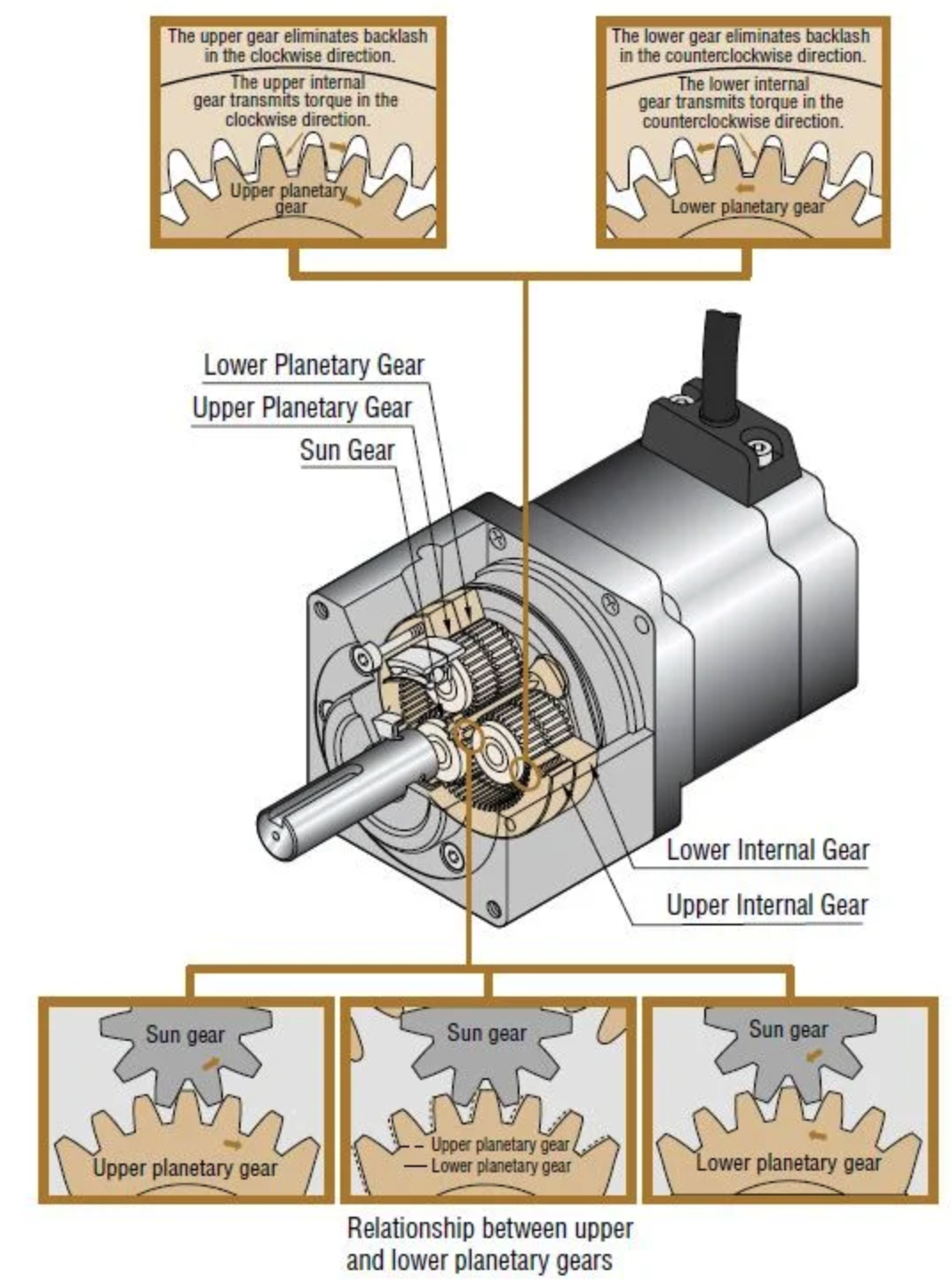 |
A robot comprises metallic components propelled by actuators, rendering it a complex dynamic system. In the case of inexpensive robots with lower precision, a plethora of unforeseen artifacts and sources of mechanical error may manifest. One such common occurrence is “backlash,” a phenomenon notoriously difficult to simulate accurately. Backlash refers to the mechanical play or slack within the system, often resulting in imprecise movements or delays in response, which can significantly impact the robot’s performance and reliability.
When a simulator consistently assumes ideal gear conditions and flawless movements, which are often easier to simulate, it sets up a scenario where any policy trained within such simulated environments may struggle when deployed to low-cost robot hardware. Consequently, policies trained solely within these idealized simulations lack the capability to handle the nuances and limitations of real-world hardware effectively. This mismatch between simulation and reality can result in significant performance degradation when deployed in practice.
Solutions. Domain randomization stands out as one of the most widely embraced strategies for tackling the physics simulation gap. Essentially, this approach deviates from the conventional practice of determining a single set of optimized physics parameters within a simulator. Instead, it introduces randomness (within a reasonable range) by varying these parameters at regular intervals. This intuitive method allows the simulator to encompass a broader spectrum of scenarios, preparing the trained models to adapt more effectively to diverse real-world conditions. By exposing the policy to a range of simulated environments with randomized physics parameters, domain randomization aims to enhance the model’s robustness and generalization capabilities when deployed in practical settings.
For example, in simulation we can randomize:
- the mass and center-of-mass (COM) of the robot and objects,
- the frictions of different objects,
- the controller parameters of the robot,
- the output action by applying small perturbations to it,
- random torques applied to the robot actuators,
- and so on…
The “regular interval” at which the randomization is applied can be determined as
- every control step,
- every episode, or
- every fixed number of control steps.
The choice of frequency for domain randomization depends largely on the specific nature of the randomization being employed. For instance, when aiming to enhance the policy’s adaptability to diverse surface frictions, we sample a new set of friction parameters at the outset of each new episode and maintain their values fixed throughout. Conversely, if the objective is to bolster the robot’s resilience against random external forces during deployment, randomizing external torques at every control step proves more advantageous. By introducing variability in external torques continuously throughout the control process, the policy is trained to handle unforeseen disturbances and adapt its actions in real-time, thus enhancing overall robustness during deployment.
It’s crucial to note that all randomness parameters are considered hidden variables, meaning they shouldn’t be directly incorporated as inputs to the policy during training. The reason behind this is straightforward: obtaining these randomness parameters in the real-world deployment scenario is typically impractical or costly. However, if the same set of randomization parameters persists over a certain duration, it becomes feasible to allow the policy to estimate them based on historical observations. In this scenario, the decision-making problem no longer adheres strictly to the Markovian property, as the policy relies on past observations to infer the current state. This adjustment introduces additional complexity but enables the policy to adapt to variations in the environment more effectively over time.
| Without friction randomization | With friction randomization (Kumar et al 2021) |
|---|---|
 |  |
 |  |
Sensor and control delays
Sensor delay refers to the time gap between the occurrence of an event in the environment and the arrival of the corresponding signal at the decision-making policy. This delay can be broken down into two main segments: sensor processing delay and sensor transmission delay. Sophisticated sensors, such as smart RGB cameras, often incorporate algorithms to process raw sensory data directly on the device. These algorithms, which may involve tasks like image compression, color adjustment, and motion deblurring, can introduce processing time depending on their complexities. Once the processing is complete, the resulting data is transmitted from the device to a computer hosting the decision-making policy. If the policy resides on a separate computer connected to the device via WiFi other than a cable, the communication cost between the two systems becomes a significant factor that cannot be overlooked.
Control delay encompasses the time interval between when the decision-making policy has received all necessary inputs and when the resulting action output is transferred to the robot. This delay can be further divided into two primary components: model inference delay and action transmission delay. Upon gathering all requisite sensor data for decision-making, the policy activates a deep learning model to generate a suitable robot action. However, if the deep learning model is substantial in size, such as large Convolutional Neural Networks (CNNs) or Transformers, the inference time can become notably prolonged, contributing to the overall control delay.
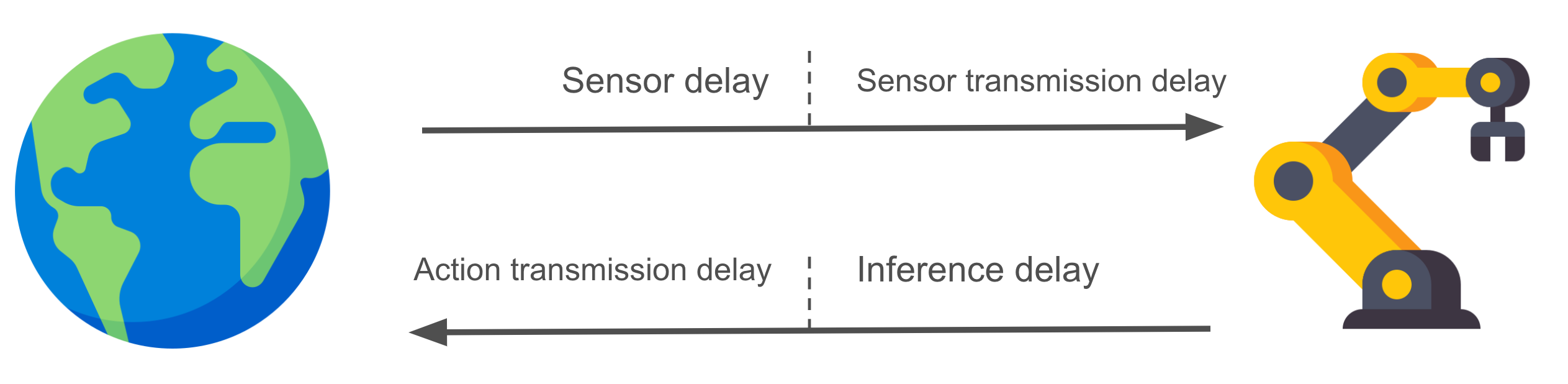
The combined sum of the two delays plays a critical role in determining the promptness with which the policy can respond to changes in the environment. Interestingly, if the goal is not to train highly reactive robots, it becomes feasible to train a policy capable of adapting to the prolonged overall delay inherent in the robot’s operation. This is feasible under the condition that the delay remains consistent and is accurately modeled within the simulator. By simulating and incorporating this stable delay into the training process, the policy can learn to adjust its decision-making timeframe accordingly, thereby accommodating the delayed response inherent in the robot’s actions.
However, the delay is not guaranteed to be always stable, mainly due to two hardware factors:
- Connectivity fluctuations, and
- Available computation resources on the computer hosting the policy.
These hardware-related variations introduce dynamic changes in delay, making it challenging for the policy to consistently adapt to a specific delay duration. As a result, the policy is prone to making incorrect decisions due to delayed observations/actions.
Solutions. One of the most straightforward solutions to address the delay issue is to upgrade the hardware components to minimize delays as much as possible. This can involve switching from a WiFi connection to a cable connection, which often offers more stable and faster data transmission rates. Additionally, directly hosting the inference policy on board the robot itself can significantly reduce delays by eliminating the need for data transmission to an external computer. Furthermore, if the policy relies on a large deep learning model for inference, distilling this model into a smaller, more efficient version can help reduce the inference delay without compromising performance significantly. Alternatively, upgrading the GPU on the robot can also enhance computational capabilities, thereby reducing inference times and overall delays in decision-making processes.
Upgrading all the hardwares can incur a substantial financial investment! For robotics companies, this can also limit the accessibility of the robot to a wider user base due to a high manufacturing cost. So, what’s the solution for an affordable robot? The answer remains: domain randomization. This time, we’ll simulate and randomize the two delays as well. Still, the randomized delays are hidden variables and the policy has to learn to adapt to them (e.g., taking slow actions or move slowly to minimize the impact of delays).
| No delay randomization | Multi-Modal Delay Randomization (Imai et al 2022) |
|---|---|
 |  |
[To be continued]
Citation
If you want to cite this blog post, please use the BibTex entry below:
@misc{robotics_sim2real_yu2024,
title = {On Sim2Real Transfer in Robotics},
author = {Haonan Yu},
year = 2024,
note = {Blog post},
howpublished = {\url{https://www.haonanyu.blog/post/sim2real/}}
}