On Sim2Real Transfer in Robotics (Part 3/3)
 Image credit: Gemini
Image credit: GeminiVision Sim2Real Gap
Two types of robot sensors
When diving into the world of robotics, it’s crucial to understand the fundamental role sensors play in guiding a robot’s actions. Broadly speaking, sensors fall into two main categories: proprioceptive and exteroceptive. Proprioceptive sensors provide the robot with internal feedback about its own state, such as joint angles, motor currents, or wheel speeds. In our previous discussions on bridging the gaps between simulation and reality in robotics, we’ve predominantly focused on proprioceptive sensors. We know that it’s important to develop simulation models that faithfully represent the complexities of the robotic system. By doing so, we can generate simulated data that closely mirrors the readings we would expect from actual proprioceptive sensors.
In contrast, exteroceptive sensors serve as the robot’s eyes and ears to perceive the world outside. These sensors, ranging from cameras and lidar to infrared sensors, capture valuable information about the robot’s environment. Through exteroceptive sensing, the robot gains insights into the terrain it traverses, the objects it encounters, and the obstacles it must navigate. Unlike the relatively low-dimensional data produced by proprioceptive sensors, exteroceptive sensors yield a significantly higher dimensionality of data. In fact, the data generated by exteroceptive sensors can be thousands of times more complex.
Most Sim2Real robots are blind
The vast dimensionality of data produced by exteroceptive sensors not only presents opportunities but also introduces a significant challenge: the vision Sim2Real gap. This gap arises when the simulated visual data fails to accurately mirror the complexities of real-world visual perception. Despite advancements in simulation technologies, accurately replicating the intricacies of visual scenes—such as lighting conditions, object textures, and environmental dynamics—remains a formidable task. As a result, the visual feedback received by robots in simulated environments often differs from what they would experience in the real world. This discrepancy can hinder the robot’s ability to effectively interpret and respond to its surroundings, leading to suboptimal performance and potential safety concerns.
| GTA 5 outdoor scene vs. real outdoor scene | ProcThor indoor scene vs. real indoor scene |
|---|---|
 |  |
It’s no surprise that many robots trained in simulation are blind to the rich visual cues that define their environment. This limitation stems from the fact that their learning policies are designed to be built solely on proprioceptive sensor inputs, which provide internal feedback about the robot’s own state but lack the crucial context provided by exteroceptive sensors. This intentional design choice, keeping only proprioceptive sensors but removing exteroceptive sensors, often serves as a workaround to mitigate the challenges posed by the vision Sim2Real gap. By relying solely on internal feedback, robots can develop locomotion policies that generalizable across varying simulated environments. However, this approach ultimately falls short of equipping robots with the perceptual capabilities necessary to thrive in the real world.
| In the impressive humanoid demo (Radosavovic et al. 2024), the robot cannot perceive surrounding environments. It relies on proprioceptive sensors to walk. |
|---|
For robots to truly excel in diverse and dynamic environments, they must transcend their reliance on proprioceptive sensors and embrace the rich tapestry of visual information available to them. Just as humans rely on vision to navigate and understand the world around them, robots too must harness the power of visual perception to perceive and interpret their surroundings accurately. This requires an effort to bridge the vision Sim2Real gap.
Vision Sim2Real transfer is an out-of-domain (OOD) generalization problem
One important assumption for current machine learning techniques is that the training data distribution and test data distribution should be similar. In-domain generalization has been demonstrated as a great success for deep learning models. However, out-of-domain (OOD) generalization has always been an unsolved challenge. Even for ChatGPT or Claude, sometimes OOD examples will trick the system to output unexpected answers.
Vision Sim2Real transfer is certainly an OOD generalization problem. There is inherently a visual domain shift: the input vision data distribution in simulation is different from that in reality (synthetic vs real pixels). This causes unpredictable outputs from the model when deployed in the real world.
| Tobin et al. 2017 |
|---|
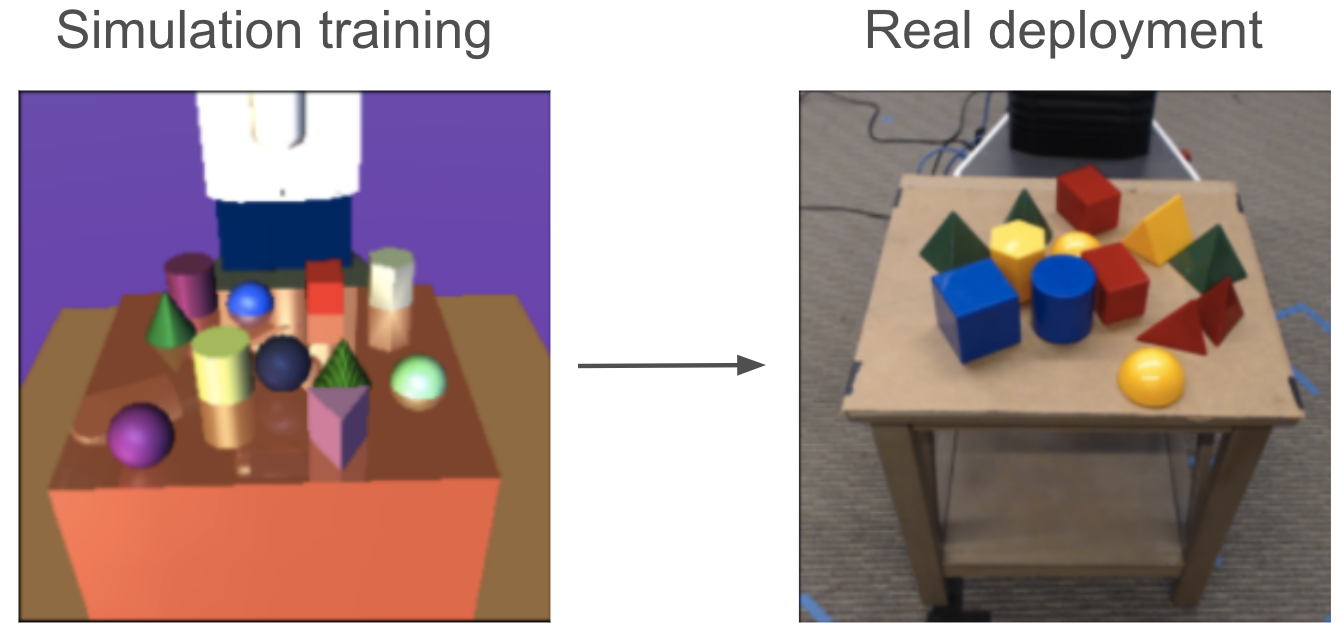 |
Depth has a smaller Sim2Real gap
When comparing depth sensors to RGB sensors in the context of Sim2Real transfer, an interesting observation emerges. Depth sensors, unlike RGB sensors, capture information that is less dependent on the appearance of the environment. This agnosticism towards environmental appearance significantly reduces the gap between simulated and real-world data. The depth data provides crucial spatial information, such as distances to objects, without being influenced by variations in lighting, textures, or colors. In fact, many robots with limited vision capabilities rely heavily on depth sensors which serve a fundamental purpose, primarily centered around obstacle avoidance.
Although simulators can generate perfect depth maps with ease, the same cannot always be said for real-world depth sensors. In practice, real depth sensor data often contains inherent noise or artifacts, which can arise from various factors such as sensor inaccuracies, environmental interferences, or hardware limitations. These imperfections introduce challenges when attempting to directly translate simulations into real-world applications. However, the good news is that despite these limitations, simple post-processing techniques can often be applied to refine and enhance the quality of real-world depth data. These post-processing tricks serve to mitigate noise, fill hollow holes, and improve the overall accuracy of the depth information captured by the sensor. By employing such techniques, the gap between simulated and real depth data can be further bridged, facilitating more seamless integration of simulated training environments with real-world scenarios.
| Zhuang et al. 2023 |
|---|
 |
Unlike depth sensors, RGB sensors need more sophisticated methods to close the Sim2Real gap, which we will briefly go over in the rest of the article.
Domain randomization
The core idea behind domain randomization (DR) is to introduce significant variability into simulated vision data during the training process. By doing so, the aim is for the neural network or learning algorithm to become robust to a wide range of conditions and scenarios. Essentially, the network is trained to adapt to different environments and situations by experiencing a plethora of variations in its training data. The hope is that when the model encounters a real-world environment, it will perceive it as just another variation, akin to the randomized environments it encountered during training.
We can divide DR further into two categories, depending on which domain we apply the randomization to.
Image domain randomization
We can add low-level perturbations (e.g., noises, blurriness, color brightness/contrast) to perceived RGB images, for a limited randomization effect. Several naive higher-level randomization strategies are also proposed, such as MixUp and CutoutColor (Fan et al. 2021). The former linearly combines a robot vision image with a random image from an offline dataset, as a proxy of simulating random backgrounds. The latter randomly places a color block in the vision image to simulate object distraction during real deployment.
| Image DR examples (Fan et al. 2021). The last two examples show CutoutColor and MixUp. |
|---|
 |
Simulator domain randomization
For those aiming to comprehensively randomize the perceptual experiences of a robot in a structured manner, the incorporation of simulator domain randomization becomes indispensable.
Simulation parameter randomization. This approach involves systematically introducing variations and fluctuations into the parameters and attributes of the simulated environment during the training process. These parameters might include: object color/texture, background color/texture, lighting conditions, shadows, etc. Simulator parameter randomization ensures that the learning algorithm encounters a wide spectrum of situations. This strategy is very similar to the one we’ve talked about for physics parameter randomization, except that the latter is mainly for bridging the physics Sim2Real gap.
| Simulator parameter randomization (Tobin et al. 2017) |
|---|
 |
Procedural scene randomization. Another powerful technique is the use of procedural generation to create diverse scene layouts. Procedural generation involves algorithmically generating environments and scenarios based on a set of predefined rules or parameters. By leveraging procedural generation techniques, researchers can create an infinite variety of scene layouts, each presenting a unique challenging scene for the robot to perceive. This approach not only increases the diversity of training data but also ensures that the robot learns to adapt to novel environments that it may encounter in the real world. Ultimately, by integrating procedural generation into the training pipeline, we can significantly enhance the robot’s ability to generalize its perception model across a wide range of scenarios and environments.
| ProcThor generated rooms (Deitke et al. 2022) |
|---|
 |
Use of scanned scenes. Broadening our perspective, we can leverage the wealth of off-line scanned realistic 3D scenes as a potent method for implementing visual domain randomization. This approach involves incorporating pre-existing datasets of meticulously scanned real-world environments into the training pipeline, thereby enriching the diversity and realism of the simulated vision data. Numerous initiatives and research endeavors have contributed to the availability of high-quality scanned 3D indoor scenes. Notable among these resources are repositories such as 3RScan, ScanNet++, and SceneVerse.
| ScanNet++ (Yeshwanth et al. 2023) |
|---|
 |
While scanned scenes offer a compelling solution for enhancing the diversity of vision data, it’s crucial to acknowledge their limitations, particularly in the context of physics simulation. When a scanned scene is imported into a simulator, it typically arrives as a cohesive chunk of mesh data, representing the entirety of the environment in a unified form. While this mesh data does provide collision shapes, which prevent the robot from colliding with the structural elements of the scene, it lacks the granularity necessary for enabling interactions with individual objects or dynamic changes to the scene state. This is because that unlike synthetic environments, where objects are represented as distinct entities with associated physics parameters, scanned scenes often lack this level of detail and granularity. Individual objects within the scene are not delineated, and their physical properties, such as mass, friction, and dynamics, are not explicitly defined.
This limitation might pose challenges for task definition. Imagine a robot task is to pick an a cup. Besides the target cup (which can be interacted with) spawned by the simulator, the scanned scene happens to also include a cup, which cannot be picked up, on a table. From the robot’s vision, there is no difference between the two cups. So it might get confused by the two dramatically different outcomes by interacting with the two cups.
Overall, different image domain randomization techniques have been widely applied for visual policy Sim2Real transfer, and some success cases have been demonstrated by the community (Tobin et al. 2017, Akkaya et al. 2019, Fan et al. 2021).
Image domain adaptation (style transfer)
Image domain adaptation represents a powerful approach to aligning the distributions of training and testing image data, thereby enhancing the generalization capability of deep learning models across different domains. At its core, domain adaptation leverages the capacity of deep learning architectures to transfer the style and characteristics of images from a source domain to a target domain. This approach can be divided into three categories as below.
Sim2Real in simulation
When training in simulation, we can style transfer the simulated RGB images to ensemble the real-world version using a pretrained GAN. So the robot policy can be trained as if the training data is collected from the real world. To pretrain the GAN, an offline dataset needs to be first collected, containing both simulated images and real images.
| GraspGAN (Bousmalis et al. 2017) |
|---|
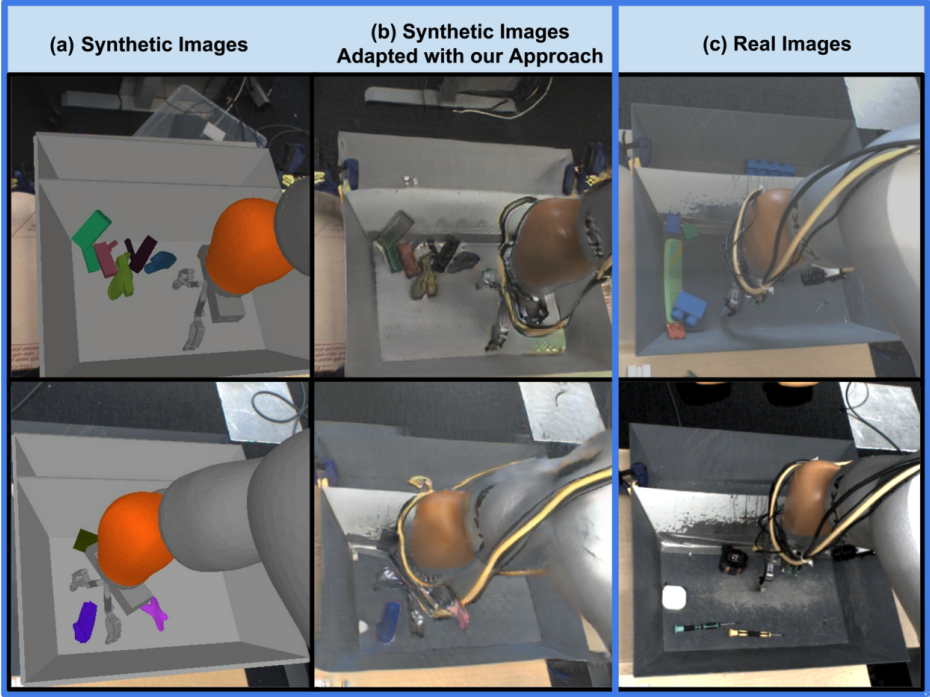 |
Real2Sim in real
This technique is similar to the one above, but in a reverse direction: when deploying the robot, we style transfer real-world RGB images to the simulator style using a pretrained GAN. One potential benefit of style transferring in this direction is that, the simulator image domain is usually much simpler than the real-world image domain, because we might just define simple colors or textures in the simulated environment. However, a downside of it is an additional inference latency introduced by the GAN during deployment. This latency might cause troubles to the overall policy execution.
Canonical representation
A third choice is to transfer both real and sim RGB images to a canonical representation. Unlike Sim2Real or Real2Sim style transfer which needs collection of real-world images for training a GAN, this canonical representation requires no real-world data. The idea is to apply heavy domain randomization to the simulation data, while simultaneously style transferring the images to a predefined canonical image space. The canonical image space is usually very clean, with objects and background rendered with simple and distinct colors. During deployment, the same style transfer network will be also applied to the real images for the canonical representation. Because we randomize the environment a lot for training in simulation, during deployment the network might just think the real images have some kind of random style and adapt it to the canonical space as well.
| RCAN (James et al. 2019) |
|---|
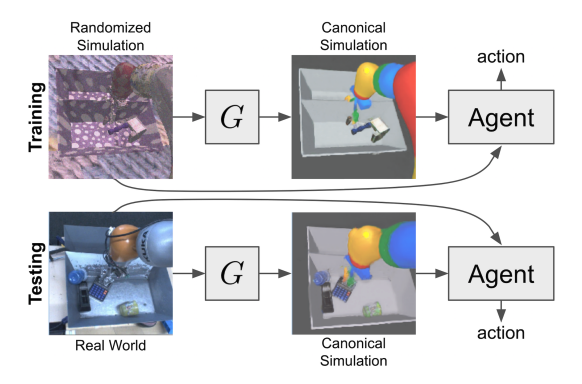 |
Summary
Over the course of this and the preceding two articles, we’ve talked about the strategies for overcoming the vision and physics Sim2Real gaps, essential for seamlessly deploying robots trained in simulation to real-world environments without the need for fine-tuning. However, it’s crucial to recognize that Sim2Real transfer remains an open challenge, with ongoing research efforts aimed at further refining and improving existing methodologies.
In scenarios where Sim2Real transfer proves elusive, an alternative avenue for training real-world robots involves the collection of vast amounts of demonstration data, followed by the application of imitation learning. This approach sidesteps the need to bridge the gap between simulation and reality altogether, as the demonstration policy and learning policy operate within the same domain. Notably, many well-funded companies, including Tesla and Figure, have embraced this methodology to train highly complex and capable robots.
Simulators offer an invaluable resource, capable of generating virtually infinite amounts of customizable training data. Moreover, reinforcement learning (RL) stands as a vital complement to imitation learning (IL), empowering robots to transcend the behaviors demonstrated by human demonstrators and to continuously adapt to novel environments. In this regard, simulators provide the perfect sandbox environment for training robots using RL algorithms, laying the groundwork for the emergence of adaptive and versatile robotic systems. Looking ahead, I hold a strong conviction that Sim2Real transfer represents a promising pathway toward the development of truly general-purpose robots in the future.
Citation
If you want to cite this blog post, please use the BibTex entry below:
@misc{robotics_sim2real_yu2024,
title = {On Sim2Real Transfer in Robotics},
author = {Haonan Yu},
year = 2024,
note = {Blog post},
howpublished = {\url{https://www.haonanyu.blog/post/sim2real/}}
}